
Ngoc-Bao Nguyen(*) |
Keshigeyan Chandrasegaran(*) |
Milad Abdollahzaden |
Ngai-Man Cheung
Singapore University of Technology and Design (SUTD)
CVPR 2023
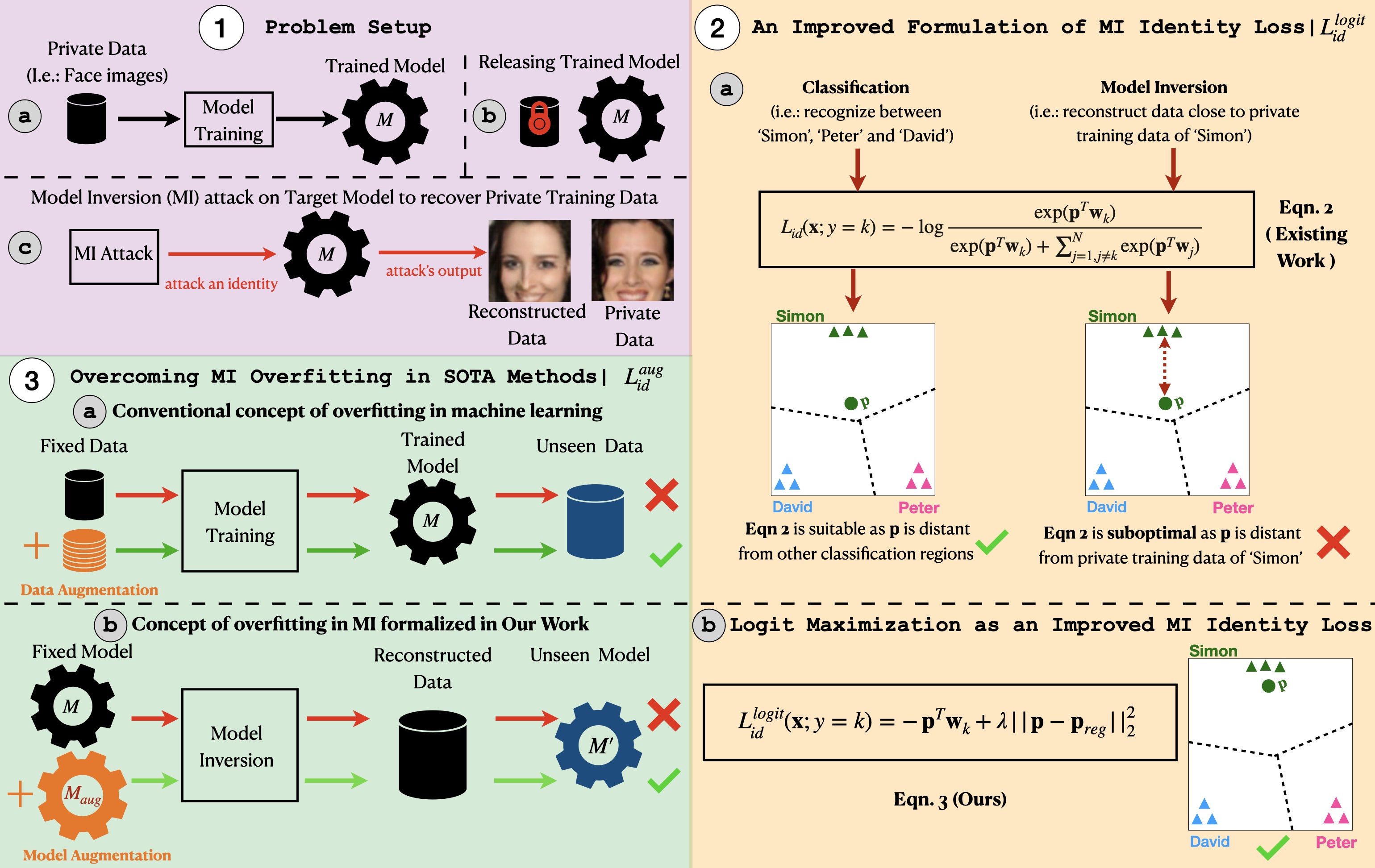
Model inversion (MI) attacks aim to infer and reconstruct private training data by abusing access to a model. MI attacks have raised concerns about the leaking of sensitive information (e.g. private face images used in training a face recognition system). Recently, several algorithms for MI have been proposed to improve the attack performance.
In this work, we revisit MI, study two fundamental issues pertaining to all state-of-the-art (SOTA) MI algorithms, and propose solutions to these issues which lead to a significant boost in attack performance for all SOTA MI. In particular, our contributions are two-fold: 1) We analyze the optimization objective of SOTA MI algorithms, argue that the objective is sub-optimal for achieving MI, and propose an improved optimization objective that boosts attack performance significantly. 2) We analyze “MI overfitting”, show that it would prevent reconstructed images from learning semantics of training data, and propose a novel “model augmentation” idea to overcome this issue. Our proposed solutions are simple and improve all SOTA MI attack accuracy significantly. E.g., in the standard CelebA benchmark, our solutions improve accuracy by 11.8% and achieve for the first time over 90% attack accuracy. Our findings demonstrate that there is a clear risk of leaking sensitive information from deep learning models. We urge serious consideration to be given to the privacy implications.
@InProceedings{Nguyen_2023_CVPR,
author = {Nguyen, Ngoc-Bao and Chandrasegaran, Keshigeyan and Abdollahzadeh, Milad and Cheung, Ngai-Man},
title = {Re-Thinking Model Inversion Attacks Against Deep Neural Networks},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2023},
pages = {16384-16393}
}
This research is supported by the National Research Foundation, Singapore under its AI Singapore Programmes (AISG Award No.: AISG2-RP-2021-021; AISG Award No.: AISG2-TC-2022-007). This project is also supported by SUTD project PIE-SGP-AI-2018-01. We thank reviewers for their valuable comments. We also thank Loo Yi and Kelly Kuo for helpful discussion.